PM 트랙_강의/데이터 분석
파이썬(Python) 실습하기 - 제품 수요가 많은 지역 찾기
은하_carol
2025. 1. 13. 17:13
데이터 전처리
1. 라이브러리 사용 선언
import pandas as pd
2. 파일 읽어오기 및 확인
sparta_data = pd.read_table('/content/students_area_detail.csv', sep = ',')
sparta_data.head()
- 컬럼 정보
- lecture_id: 수강 강의 Id
- area: 접속 지역
- latitude: 해당 지역 위도
- longitude: 해당 지역 경도
- user_id: 유저 Id
3. 데이터 전처리
- 현재 데이터 분석에 필요한 정보는 user_id(유저 Id), area(접속 지역), latitude(해당 지역 위도), longitude(해당 지역 경도)
- set() 함수는 데이터의 중복 없이 각각의 데이터가 unique한 값을 가질 수 있게 하는 함수
- len() 함수는 리스트에 들어가 있는 원소 개수, 즉 리스트의 크기를 알려 주는 함수
# 작성 코드
# 지정한 컬럼 데이터 중복 제거 후 리스트로 나열
category_range = set(sparta_data['area'])
print(category_range, len(category_range))
# 실행 결과
{'제주', '부산', '전북', '서울', '경남', '대전', '경기', '세종', '충북', '광주', '경북', '강원'} 12- 필요한 정보만 추출해서 새 테이블을 생성할 때는 기존 테이블에서 필요한 "컬럼명"을 대괄호에 넣어 변수 지정
# 필요한 정보만 추출하여 새 테이블 생성
area_info = sparta_data[['area', 'latitude', 'longitude']]
area_info.head()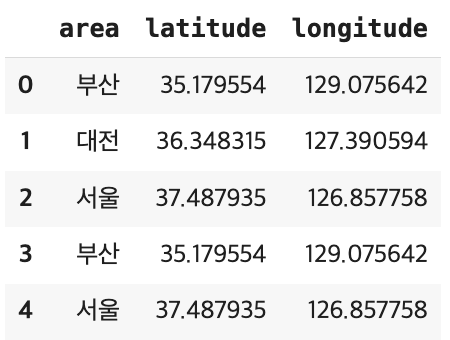
- 중복되는 테이블의 정보를 삭제하기 위해서는 drop_duplicates() 함수 사용
area_info = area_info.drop_duplicates(['area'])
area_info.head()
- 중복 제거로 인해 뒤엉킨 index를 재정렬하기 위해서는 reset_index() 함수 사용
area_info = area_info.reset_index()
area_info.head()
- sort_values(by = ['정렬 기준 컬럼명'], ascending = [정렬 유형]) 함수를 활용하면 데이터 정렬 가능
- 정렬 유형: 오름차순(ascending = [True]), 내림차순(ascending = [False])
area_info = area_info.sort_values(by = ["area"], ascending = [True])
area_info.head()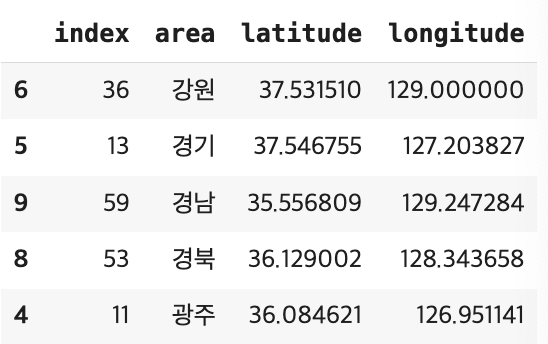
- pd.DataFrame() 함수를 사용해 테이블 내 데이터를 조회할 수 있고, groupby()와 count()를 활용하여 지역별 총 학생 수 조회
# 각 지역별 총 학생 수 구하기
number_of_students = pd.DataFrame(sparta_data.groupby('area')['user_id'].count())
number_of_students
- pd.merge() 함수는 두 테이블을 병합하는 함수
- 지역별 총 학생 수를 기존 테이블과 합하여 조회
# 지역별 총 학생 수를 기존 테이블과 병합
result = pd.merge(area_info, number_of_students, on = "area")
result
데이터 시각화
1. 라이브러리 사용 선언
import matplotlib.pyplot as plt
import numpy as np
# 한글 깨짐을 방지
plt.rc('font', family='NanumBarunGothic')
2. 지역별 수강생 수 라인 그래프 그리기
# 그래프 사이즈 변경
plt.figure(figsize=(10,5))
# 그래프 x축 y축
plt.plot(result['area'], result['user_id'])
# 그래프 명
plt.title('지역별 사용자 수')
# 그래프 x축 레이블
plt.xlabel('지역')
# 그래프 y축 레이블
plt.ylabel('사용자(명)')
# x축 눈금 수
plt.xticks(np.arange(13))
# 그래프 출력
plt.show()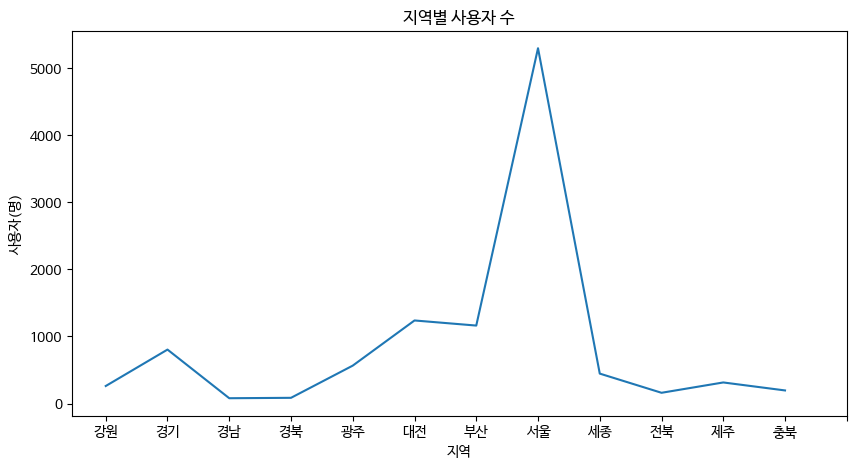
데이터 지도에 표시
1. 라이브러리 사용 선언
- 폴리움(Folium)이란 분석한 데이터의 결과를 지도에 그리기 위한 라이브러리
- 마커 클러스터(MarkerCluster)란 가까운 거리의 marker들을 군집시켜 해당 건수를 표현해 주는 라이브러리
import folium
from folium.plugins import MarkerCluster
2. 대한민국 위도, 경도 설정
- folium.Map(location = [위도, 경도], zoom_start = 확대 정도) 함수는 지도를 그려 주는 함수
m = folium.Map(location=[37.5536067,126.9674308],
zoom_start=8)
m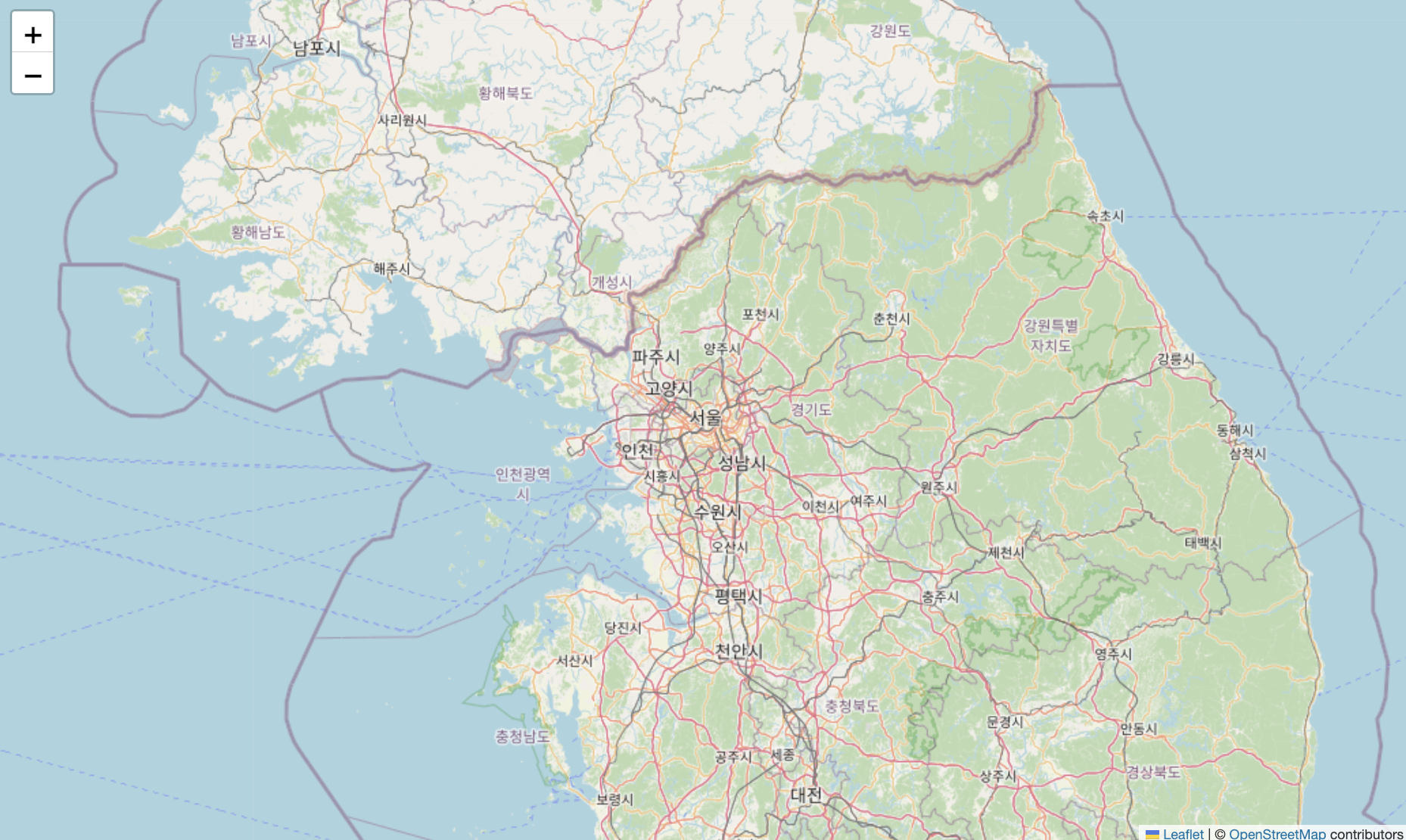
3. 지도에 수강생 분포 그리기
- 반복문을 이용하여 분포 그리기
for n in result.index:
radius = result.loc[n, 'user_id']
# loc[n, "열 이름"] => loc[]를 활용하여 n번째의 열을 조회
# 즉, n번째의 user의 수 가져오기
folium.CircleMarker([result['latitude'][n], result['longitude'][n]],
radius = radius/50, fill = True).add_to(m)
#.add_to(m)를 활용하여, 지정해 두었던 우리나라의 지도 가져오기
m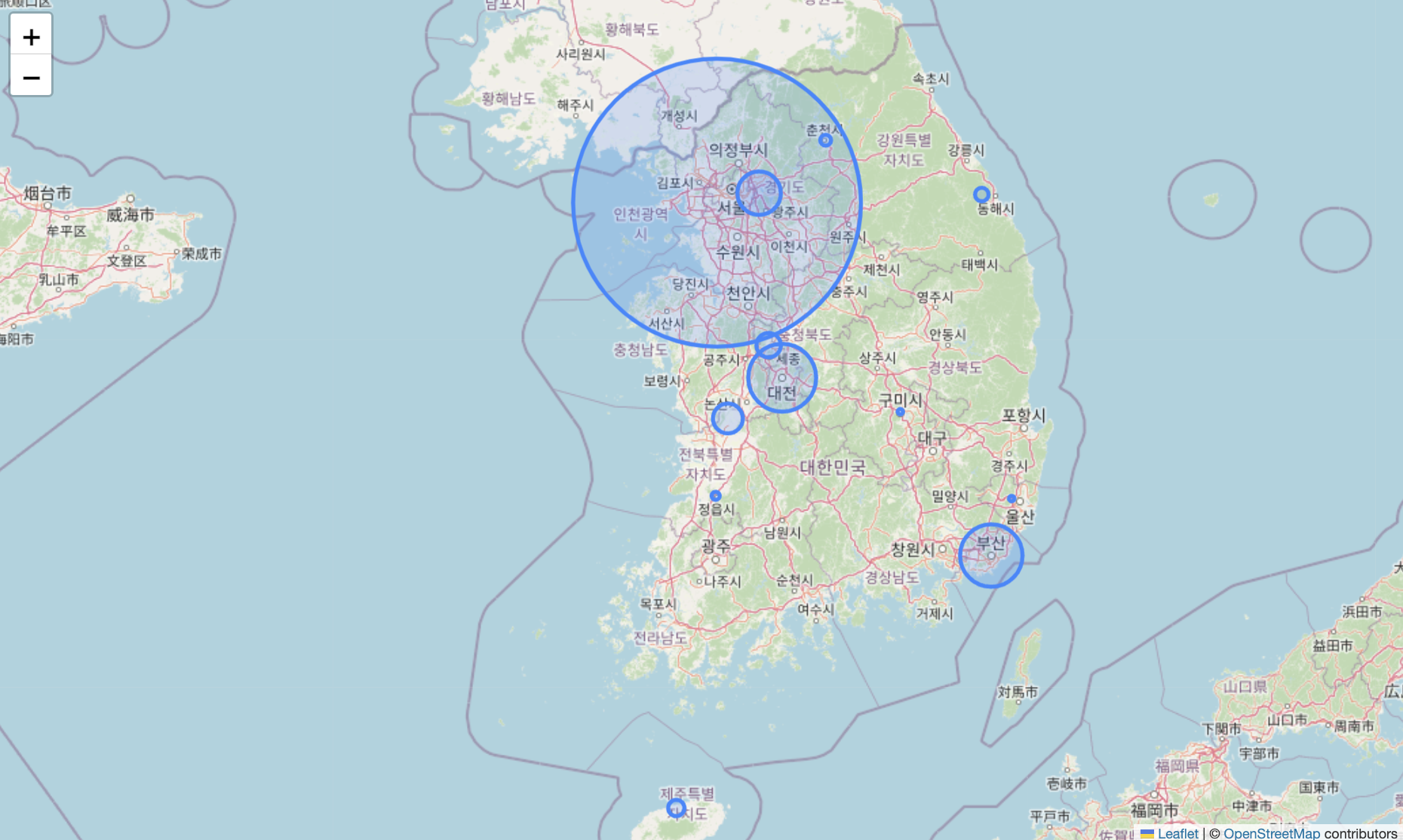
4. 결론
- 서울 지역에서 수강생의 숫자가 가장 많다.
- 다음으로는 대전, 부산 지역 순으로 수강생이 많이 분포해 있다.